Hash table
A hash table is a data structure that implements the map abstract data type. Given a piece of data known as a key, a map may be used to look up a corresponding piece of data called the value. This functionality is implemented by computing a hash function on a key to obtain an index in an array where the value may be stored. The value of the hash function on a key is completely determined by the identity of the key, so the hash function is a function in the mathematical sense where each key has one hash value. The motivation for using a hash table instead of a balanced binary search tree as map is that the average time complexity of looking up the value of a key is constant whereas the time complexity of a search in a tree is logarithmic with respect to the size of the tree.
Example
import java.util.HashMap;
import java.util.Map;
// ...
// grades is a hash table mapping names to grades
// Notice that the type of grades is the Map abstract data type,
// and the type of the instance is the concrete HashMap data type.
Map<String, Double> grades = new HashMap<String, Double>();
// Insert Alice's grade
grades.put("Alice", 86.0);
// Retrieve Alice's grade
double aliceGrade = grades.get("Alice");
// Update Alice's grade
double bonus = 5.0;
grades.put("Alice", aliceGrade + bonus);
grades.put("Bob", 25.0);
grades.put("Charlie", 76.0);
grades.put("David", 98.0);
// Remove Bob from the class
grades.remove("Bob");
// Error! Bob is no longer in the table
// grades.get("Bob");
Sample Implementation
The following Java class HashTable taking generic parameters K and V corresponding to the key and value types, respectively, is an implementation of a hash table supporting the put, get, and remove methods. Given a key and a value, the put operation searches the table for a an existing pair of the key and some other value. If the value exists then it is replaced by the new value, and otherwise a new entry is created containing the new pair. The get method searches the table for a key, and if an entry exists it returns the value. Otherwise it returns null. Lastly, the move method searches the table for an entry corresponding to a key, and removes it from the table, if it exists. The corresponding value is returned if an entry is removed, and if no entry exists then null is returned.
It uses a table of linked list, and each key is mapped to a linked list by reducing the hash of the key modulo the length of the table. Each linked list contains pairing of keys and values, and after mapping a key to a linked list, the key is searched for in the linked list. This method is known as chaining. Performance of this data structure is dependent on the load factor, or the ratio between the length of the table and the number of entries. If the load factor is high then the probability of inspecting several elements in a linked list is high, but if the load factor is low the table is sparse and is using too much memory. To compensate for these issues, this implementation constrains the load factor to be between 0.125 and 0.5 by doubling or halving the length of the table depending on whether the load factor is above or below this range.
import java.util.Iterator;
import java.util.LinkedList;
class HashTable<K, V> {
private class Entry<K, V> {
public K key;
public V value;
public Entry(K key, V value) {
this.key = key;
this.value = value;
}
}
// Note that the table of linked lists contains null entries
private LinkedList<Entry<K, V>>[] table;
private int size;
// Remember that if the table is empty, then the table variable is null
public HashTable() {
table = null;
size = 0;
}
The get functionality works by first computing the hash of the key, and then by finding the linked list that contains the key. If the linked list is not null then the list is traversed, and if an entry containing the key is found, it returns the corresponding value.
public V get(K key) {
Entry<K, V> searchResult = findEntry(key);
if (searchResult == null)
return null;
else
return searchResult.value;
}
private Entry<K, V> findEntry(K key) {
// Compute hash function of key
int hash = key.hashCode();
return searchList(key, findList(hash));
}
private LinkedList<Entry<K, V>> findList(int hash) {
// Find entry of table corresponding to hash
if (table == null)
return null;
else
return table[hash % table.length];
}
private Entry<K, V> searchList(K key, LinkedList<Entry<K, V>> list) {
if (list == null)
return null;
// Conduct search through linked list for entry with key and value.
for (Iterator<Entry<K, V>> i = list.iterator(); i.hasNext();) {
Entry<K, V> current = i.next();
if (current.key.equals(key))
return current;
}
return null;
}
The put operation functions similarly to the get operation by first attempting to check if an entry exists by using the same search method as get, and then updating the entry with the new value. If no entry is found, a new entry is inserted into the table. First the new load factor is checked to ensure that adding the new value will not make the table too dense. If the table needs to be resized, a new table is created with twice the length to replace the old table, and the entries in the old table are inserted into the new table. This may seem quite costly, but in the analysis section, it will become clear that this does not affect the average time complexity of insertion. After resizing, if necessary, the hash of the key is used to determine where the corresponding linked list is in the table, and a new entry is inserted into the list.
public void put(K key, V value) {
Entry<K, V> searchResult = findEntry(key);
if (searchResult != null) {
searchResult.value = value;
}
else {
insert(key, value);
}
}
private void insert(K key, V value) {
++size;
if (tooSmall())
resize(table == null ? 1 : 2 * table.length);
int hash = key.hashCode();
addList(key, value, hash);
}
private boolean tooSmall() {
if (table != null)
return (double)size() / table.length > 0.5;
else
return true;
}
public int size() {
return size;
}
private void addList(K key, V value, int hash) {
int index = hash % table.length;
if (table[index] == null)
table[index] = new LinkedList<Entry<K, V>>();
table[index].add(new Entry<K, V>(key, value));
}
private void resize(int newSize) {
HashTable replacement = new HashTable();
if (newSize != 0)
replacement.table = (LinkedList<Entry<K, V>>[])new LinkedList[newSize];
// insert all keys and values into replacement table
for (int i = 0; table != null && i < table.length; i++) {
if (table[i] == null)
continue;
for (Iterator<Entry<K, V>> j = table[i].iterator(); j.hasNext();) {
Entry<K, V> current = j.next();
replacement.insert(current.key, current.value);
}
}
table = replacement.table;
}
Lastly, the implementation of remove is similar to put. First the table searches for an entry corresponding to the key by hashing and traversing a linked list, and if an entry exists it is removed from the list. In this case, the load factor of the table has changed, and it may be necessary to shrink the table using the same method utilized by get to grow the table.
public V remove(K key) {
int hash = key.hashCode();
Entry<K, V> removed = removeList(key, findList(hash));
if (removed != null) {
--size;
if (tooBig())
resize(table.length / 2);
return removed.value;
}
else
return null;
}
boolean tooBig() {
return (double)size() / table.length < 0.125;
}
private Entry<K, V> removeList(K key, LinkedList<Entry<K, V>> list) {
if (list == null)
return null;
for (Iterator<Entry<K, V>> i = list.iterator(); i.hasNext();) {
Entry<K, V> current = i.next();
if (current.key.equals(key)) {
i.remove();
return current;
}
}
return null;
}
}
Analysis
Suppose that the table contains 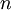 entries. First it may be demonstrated that the table resizing scheme does not affect the average time complexity of the hash table operations. When the table is resized, every index of the table is checked, and every entry is inserted into the new table. The load factor is 0.5 so at most
entries. First it may be demonstrated that the table resizing scheme does not affect the average time complexity of the hash table operations. When the table is resized, every index of the table is checked, and every entry is inserted into the new table. The load factor is 0.5 so at most  indices are checked in the table, and insertions into the new table occur. The preliminary search of the put method may be omitted, and insert method may be used instead because each key in the hash table occurs only once. Hashing and finding the linked list take constant time and we may insert the entry at the end of the linked list, so each insertion takes constant time.
indices are checked in the table, and insertions into the new table occur. The preliminary search of the put method may be omitted, and insert method may be used instead because each key in the hash table occurs only once. Hashing and finding the linked list take constant time and we may insert the entry at the end of the linked list, so each insertion takes constant time.
The banker's method of amortized analysis is a method of showing that the cost of bad cases (e.g. resizing the table) is less expensive then the aggregate cost of good cases by analogy to banking. A short-sighted liberal might withdraw more money from his bank account than he has saved, incurring overdraft fees, but a wise conservative may manage his money more carefully. Every call to put corresponds to depositing $6 in the bank, and every doubling of the array is analogous to withdrawing $3 for every entry in the hash table. Each entry costs $3 because indices in the table are checked, and elements are added to the new table. If the length of a table is doubled, then the new load factor is 0.25, and a subsequent doubling occurs when the load factor reaches 0.5 after insertion of  additional elements. Inserting elements increases the balance of the account by $6 so by spreading the cost of the doubling over the insertions, the withdrawal is affordable. As careful balancing of accounts is useful for government spending, this principle is so widely applicable that it is even helpful for analysis of algorithms. Amortized time complexity is stronger than average time complexity in the sense that the average time complexity of any sequence of operations is constant, but average time complexity is merely the average time complexity over all inputs. This distinction is made more clear in the example following the analysis of searching the hash table.
additional elements. Inserting elements increases the balance of the account by $6 so by spreading the cost of the doubling over the insertions, the withdrawal is affordable. As careful balancing of accounts is useful for government spending, this principle is so widely applicable that it is even helpful for analysis of algorithms. Amortized time complexity is stronger than average time complexity in the sense that the average time complexity of any sequence of operations is constant, but average time complexity is merely the average time complexity over all inputs. This distinction is made more clear in the example following the analysis of searching the hash table.
The worst case of a search is that none of the elements in the linked list match the key, and the entire list must be checked. If the load factor of the table is  , then the average length of each linked list is , so the average number of comparisons is bounded above by the maximum load factor, and thus the average search time is constant. This implicitly depends on the hash function assigning keys to linked lists uniformly, and a skewed hash function breaks the assumptions in the analysis. As an example, consider a hash function such that the hash of every key is 0. Every key is mapped to the same linked list, so the expected search time is
, then the average length of each linked list is , so the average number of comparisons is bounded above by the maximum load factor, and thus the average search time is constant. This implicitly depends on the hash function assigning keys to linked lists uniformly, and a skewed hash function breaks the assumptions in the analysis. As an example, consider a hash function such that the hash of every key is 0. Every key is mapped to the same linked list, so the expected search time is  , and an unscrupulous user of the hash table could exploit this to slow down searches.
, and an unscrupulous user of the hash table could exploit this to slow down searches.